Multi-turn QA Chatbot for Cold-Start Product Recommendation
Detailed clarification through conversational AI to solve the cold-start problem
Challenges
The cold-start problem refers to the difficulty of providing relevant recommendations when there's little or no historical data about a new user or a new product. Traditional recommendation systems struggle with this scenario, leading to poor user experiences and missed opportunities.
Key Challenges
- No User History: Inability to leverage past behavior for new users
- Vague Initial Queries: Users often provide minimal information initially
- Dynamic Preferences: Needs and preferences that emerge during conversation
- Real-time Processing: Requirement for immediate responses during multi-turn dialogues
Solution & Architecture
The chatbot addresses the cold-start problem by using a multi-turn Q&A approach to dynamically gather user preferences and context, immediately matching them with product knowledge through hybrid retrieval techniques.
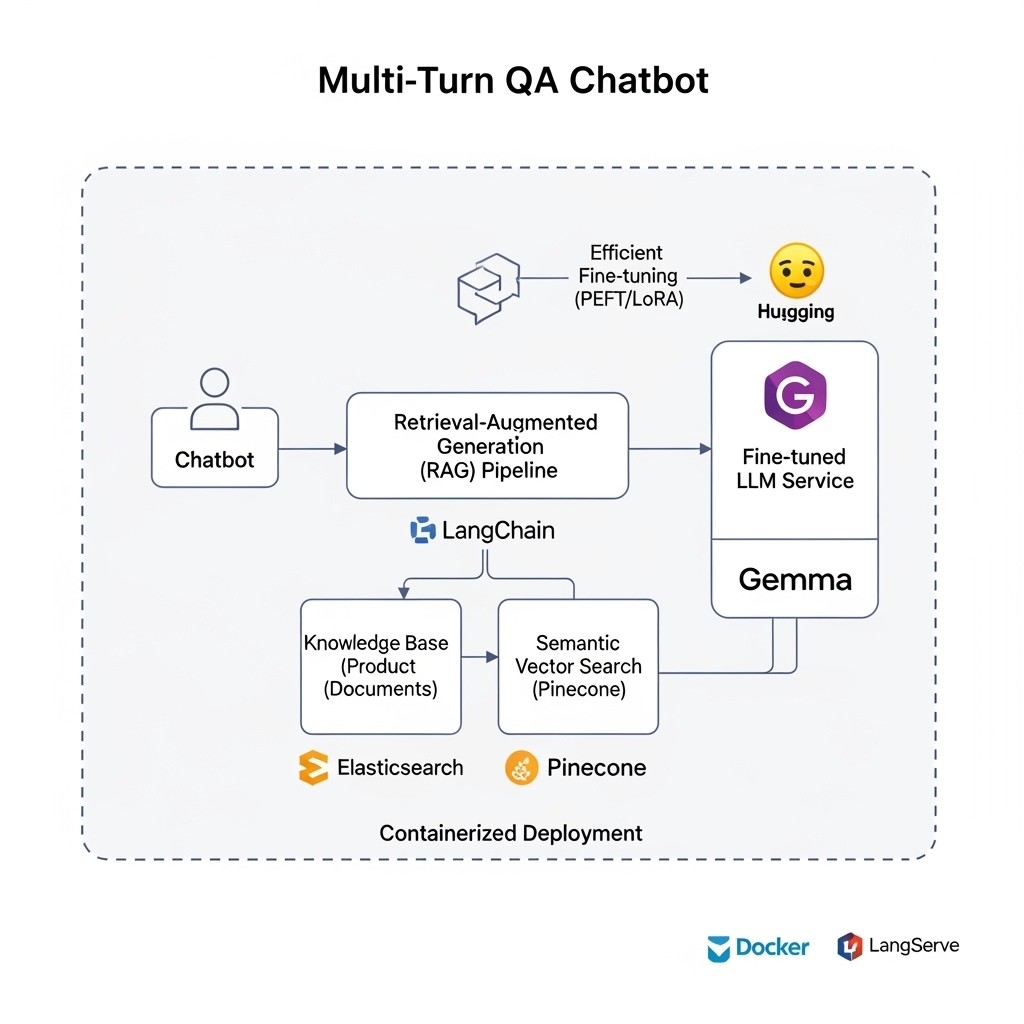
Architecture diagram showing the hybrid retrieval system for product recommendations
Key Components
-
Multi-turn Conversation Engine
Instead of waiting for user interaction history, the chatbot actively engages the user in a conversation to progressively understand needs, preferences, budget, and intended use.
-
LLM Fine-tuning
Advanced open-source LLMs (Gemma, Mistral, Zephyr) undergo efficient fine-tuning via Hugging Face Transformers to adapt to product information and recommendation dialogue.
-
Hybrid Retrieval System
Combines Elasticsearch for keyword-based sparse filtering with Pinecone for semantic dense-vector retrieval, orchestrated by LangChain for optimal relevance.
-
Containerized Deployment
The entire RetrievalQA service is containerized using Docker and deployed with LangServe for scalable, efficient inference.
Implementation Highlights
Hybrid Retrieval Optimization
Combines the precision of keyword search with the contextual understanding of semantic search, using Reciprocal Rank Fusion to merge and re-rank results from both approaches.
Efficient Fine-tuning
Utilizes parameter-efficient fine-tuning techniques (PEFT/LoRA) to adapt general-purpose LLMs to the specific domain of product recommendations with minimal computational overhead.
User Scenario
Real-World Example: Laptop Recommendation
"I'm looking for a new laptop, but I'm not sure where to start. I need it for school and some light gaming."
The chatbot asks clarifying questions about portability needs, budget range, and specific games to understand requirements.
Hybrid retrieval combines keyword matching ("laptop", "gaming") with semantic understanding of "light gaming" and "school work" to find relevant products.
The system recommends specific laptop models that balance performance, portability, and budget, with explanations of why they match the user's needs.
Results & Impact
Quantitative Results
- 35% Higher Engagement: Increased conversation duration and completion rates
- 28% Improvement: Higher conversion rates for new users compared to traditional systems
- 62% Accuracy: Precision in matching user needs with relevant products
- <1.5s Latency: Response time during multi-turn conversations
Qualitative Benefits
- Personalized Experience: Tailored recommendations based on dynamic conversation
- Reduced Bounce Rate: Lower abandonment from new users
- Increased Trust: Transparent questioning process builds user confidence
- Scalable Solution: Handles fluctuating user demand efficiently